Big data: it’s the glue of the digital universe. If you’re reading this, chances are that you are one of the two billion people in the world who live and work online and, according to the International Data Corporation, generate an annual “digital shadow” of around 1.8 million gigabytes each – whether it’s the data from streaming digital TV or just your smartphone pinging your location to Google.
Related: I Like Big Data and I Cannot Lie
For Curtin researchers Dr Andrew Hutchison, Dr Andrew Woods, Dr Petra Helmholz and Joshua Hollick (who is also undertaking a PhD), their digital shadows are going to be larger than most this year. Unlike most of us, their big data isn’t just restricted to the mass data generated on the Internet and from smart devices. In cooperation with the Western Australian Museum, they are looking to create their own sets of big data and – with the aid of the Curtin HIVE’s 3D technology – generate virtual reconstructions of the shipwrecks HMAS Sydney (II) and HSK Kormoran.
Related: Researchers abuzz over HIVE and immersive visualisation.
Sixty-seven years lost at sea
In 1941 Australian HMAS Sydney (II) sunk with all hands in an encounter with German HSK Kormoran approximately 200 km off the Western Australian coast. Both ships sank in the encounter and until 2008 their final resting places were unknown.

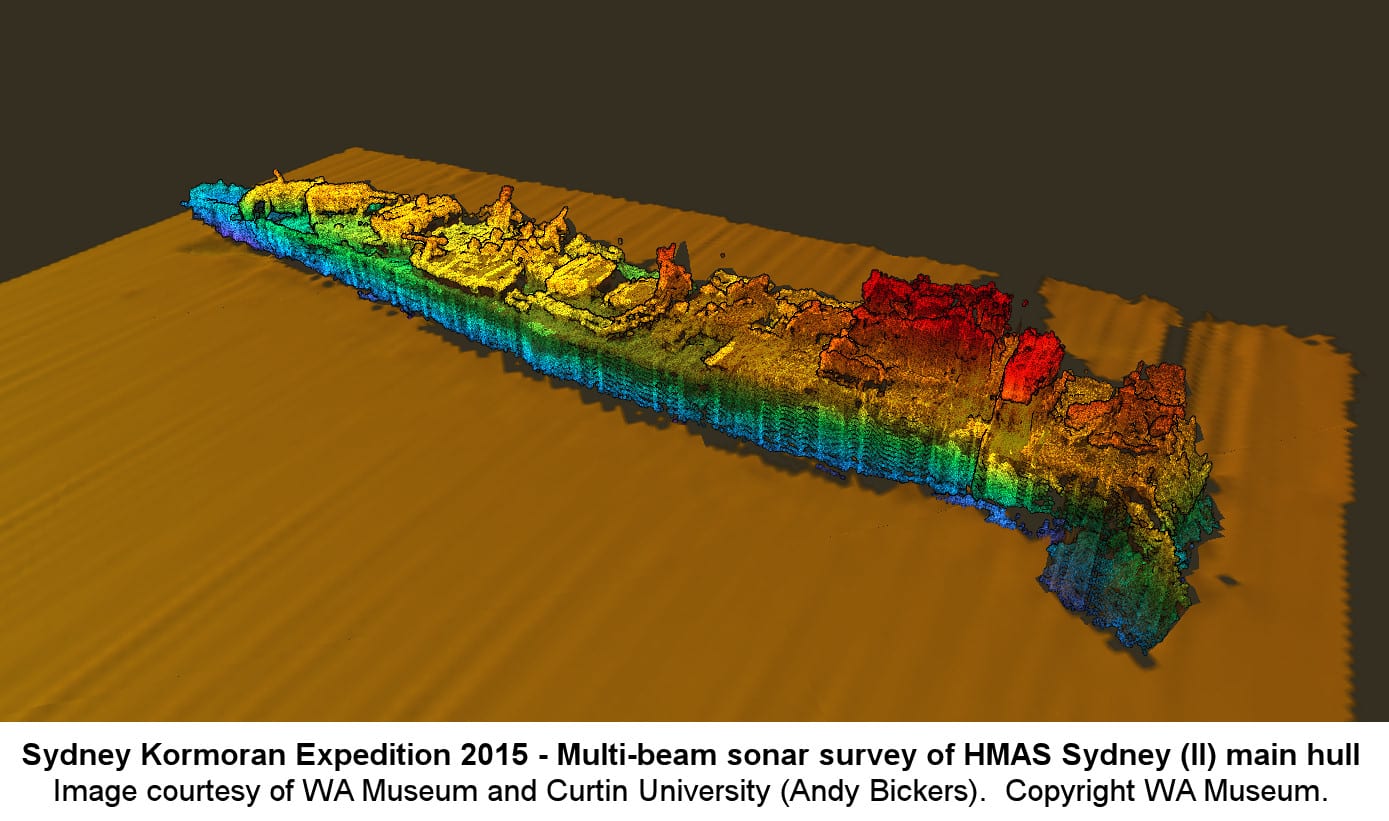
“We’ve just revisited the wreck sites of the HMAS Sydney (II) and HSK Kormoran and taken many many images to create impressive 3D models for both ships,” Hollick says.
“We’re planning to use the 3D models to create a museum exhibit so people can experience what the wreck sites are like, because being 2.5km underwater they are something that almost no one can get to.”
Related: Two Lost Ships

Beating the big data problem
In their four-day expedition to the shipwrecks, the team has accumulated approximately 50 terabytes of data from two underwater remotely operated vehicles (ROVs), each equipped with seven digital still cameras and two 3DHD video cameras (in addition to the other cameras already installed on the robots). Fresh off the back of the expedition Hollick estimates he has almost 700,000 images to process and analyse – along with 3D multibeam sonar surveys of each wreck site.
“And that’s where we start falling into the realm of big data,” says Hollick.

Watch: ROV footage of the HMAS Sydney (II), 1 May 2015
As powerful as the HIVE is, with almost 700,000 images to process to generate his 3D models, if they only used their existing processing techniques Hollick expects the rendering time would be about 1.8 millennia.
It’s a common problem for big data. The sheer volume of it is too much to process. Fortunately Hollick has a few ideas of how to get around this.
First is to use a supercomputer, specifically the Pawsey Supercomputer, located here in Perth. However, cutting the rendering time of the images depends on how many of the supercomputer’s “nodes” can be allocated to process the images – and even with enough nodes it’s only slightly quicker.
Enter metadata: librarian of the digital universe.
“Essentially, we are trying to be smarter with what data we collect and process,” Hollick says. The usual process of sorting the images for a 3D model is a bit like putting a jigsaw puzzle together, each image needs to be compared and matched against every other image until it finds where it fits – which is fine until your puzzle has 700,000 pieces in it.
Using the sonar system of the underwater ROVs, Hollick is able to geo-tag where the images were taken with an accuracy of around ten metres. When it’s time to link all the images together for the 3D reconstruction, the computer will compare images taken at similar locations, rather than images from opposite ends of the wreck. So rather than sorting through 700,000 puzzle pieces at random, the computer now knows that say these 10,000 images are all pieces from the same corner.
But even knowing where those 10,000 images were taken, it is still a puzzle – just slightly smaller. Why not take it one step further?
In any sort of bulk photography or filming, images close together in time will also be close together in position. And by collecting timestamp data from the images of the HMAS Sydney (II) and HSK Kormoran, Hollick can teach the computer to recognise this.
“The idea is that when you are comparing images, each image will match with the next image in the sequence or series,” Hollick says.
It’s not unlike an old film reel. Each frame is an image and when strung together they form a motion picture. Instead of the computer being dominated by having to compare this image here to that image all the way over there – at the other end of the reel – the timestamp instructs the computer to only compare images that are close to one another in the sequence.
Last of all, a new algorithm is needed so the computer can combine all these different forms of data (and metadata) in an intelligent way. This is the focus of Hollick’s PhD. Essentially Hollick’s algorithm links the images and data (multibeam sonar, geo-tags, and timestamps) together to guide the 3D reconstruction processes.
But the algorithm does more than simply speed up the 3D reconstruction side of things. It also creates a more accurate 3D model, and that’s because errors can affect the data. Moreover, each type of data can present errors unique to its data-type. But, with the algorithm and its ability to pull information from multiple datasets and compare it, Hollick can reduce, or even remove, these errors entirely.
“The algorithm will help us find any inconsistencies between the metadata, and the images and trajectory that each ROV recorded when they navigated through the shipwrecks,” Hollick says.
And why is that so important? Well, without the algorithm to iron out the kinks, you might wind up with a wonky ship.
“With it [the algorithm] we should also be able to correct distortions in the model by combining the different datasets and possibly fill in missing geometry using the multibeam data,” Hollick explains.
In a nutshell, where one piece of data fails, others can take its place.
So what will you get when you combine big data, metadata to catalogue it, an algorithm to collate it, and the raw processing power of a supercomputer?
Put on a pair of 3D glasses in the HIVE and, by Jove, we’ve got ourselves a ship.


